とりあえず思いつく範囲のことを書いていきます
モデルを探す
CivitaiやHugging Faceで探すのが基本です。
作者が自身のTwitterで案内を出している場合などもあります。
またモデルを利用して画像投稿する人がモデルについて言及していること、あるいはAI画像投稿プラットフォーム上で使用モデルが表記されていることもあります。
それらを参考にして探してみるのも良いと思います。
またLoRAなどの探し方も基本的には同じです。
別ページでモデルやLoRAについて使ったものを紹介しているので、そちらからある程度探すこともできるかもしれません。
StableDiffusionで使用したモデル一覧
StableDiffusionで使ってみたLoRAなど
VAEについて
VAEを導入することで、出力した画像のモヤモヤがなくなって良い感じの発色になります。
汎用的なVAEを用意するか、モデルが推奨しているもの(場合によっては専用のもの)を用意します。
ファイル形式は .pt .safetensors の2種類が存在します。
ダウンロードしたファイルは stable-diffusion-webui/models/VAE に配置して利用します。
有名なVAEの1つに vae-ft-mse-840000 というものがあるので、とりあえず最初はこれを用意しておけば最低限なんとかなると思います。
フォルダに配置しただけでは利用できないので、WebUI上から選択する必要があります。
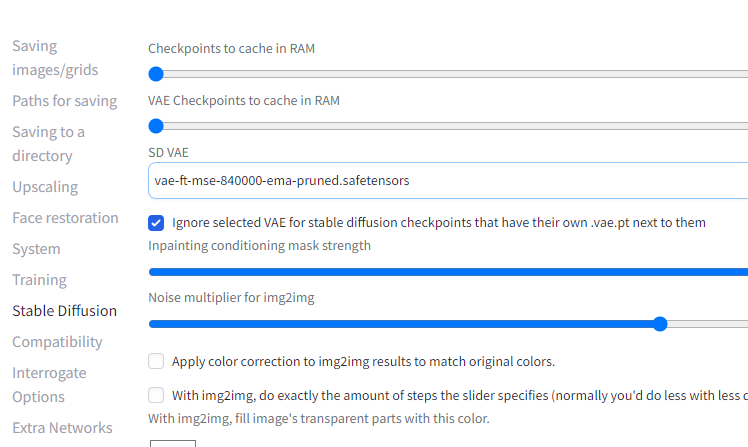
SettingsタブからStableDiffusionの項目を選択、SD VAE から任意のものを選択します。
Noneを選択すると何も選ばれていない状態になりますが、Automaticを選んでも何も選択されていない状態になります。
Automaticを選択した場合だと、VAEをモデルが配置されているフォルダに”モデルと同名”にして用意する必要があります。
ちなみにモデルによってはVAEが内臓されているものもあります。
生成画像の保存設定
settingsから生成画像の保存についても変更できます。
基本的にはPNG形式で保存することになると思いますが、ファイル形式を指定すれば例えばJPGEで保存することもできます。
設定の下の方にはJPEGの画像品質を調整する項目もあります。
また出力する画像ファイルのファイル名についてもここから調整できます。
私は [model_name]-sampler-[sampler]-steps[steps]-scale[cfg]-seed[seed] と設定しています。
これによって出力された画像のファイル名は「00001-モデル名-サンプラー名-steps数-scale数-seed値」となります。
特にモデルやseed値は結構便利に感じています。
この他に[prompt][prompt_spaces][prompt_words][width][height][styles][model_hash][job_timestamp][datetime]2024/07/01があるので好きな組み合わせで命名してください。
ちなみに出力先のフォルダは Stable-diffusion-webui/outputs になります。
よくわからない時はWebUIにフォルダを開くボタンがあるのでクリックしてください。
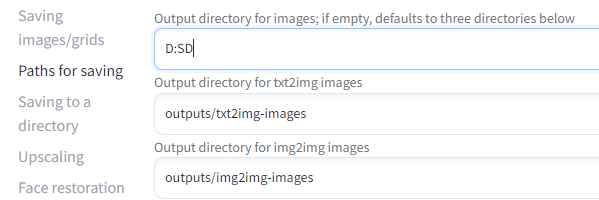
画像の出力先を変更することもできます。
Settings から Paths for saving を選択して、ディレクトリを指定します。
私はDドライブ直下にSDというフォルダを作って全部そこに放り込んでいます。
基本的に余裕があれば生成した画像は全部残しておくのがいいと思います。
昔生成したものからプロンプト引っ張ってきたり、これを執筆している現在はReference-onlyなどで過去の出力画像をリメイクしたり使い道があったりします。
ライセンスについて
これは絶対触れておかないといけない部分だと思うので、少し触れておきます。
配布されているモデルやLoRAなどにはライセンスがあります。
クレジット表記が必要かどうか、生成物を商用利用して良いかどうか、データを組み込んだサービスを商用展開して良いかどうか、モデルの場合などはマージを行ったものを公開して良いかといった部分にも及びます。
これらのライセンスは基本的に配布ページに記載されていますが、記載がないケースもあります。
そういった場合は趣味の範囲を超える場合には個別に確認する必要があるでしょう。
また途中からライセンスが変更になることもあります。
基本的にはダウンロード時の規約で問題ない範囲の利用なら大丈夫だとは思いますが、常にアンテナをはっている必要はありそうです。
またアップスケーラーなどにもライセンスはあります。
めっちゃ簡単に言うと、基本的に配布されているものは全部ライセンスを確認する必要があるということです。
特に商用利用する場合はかなりシビアに見ておかないと危険です。
普段ライセンス関係に触れていない人だと「CreativeML Open RAIL-M」もよくわからない人が多いかなと思います。
これ生成AIを使っているとよく見かけるライセンスで、わりと自由に使うことができます。
例えば生成物の商用利用なども可能です。
詳しくは原文を読むかChatGPTあたりを使って要約してみるといいと思います。
イラスト生成時の Restore faces について
Restore faces という項目があり、これにチェックを入れると顔を補正してくれます。
が、イラスト画像生成においては劣化します。
基本的にはチェックを入れない方が良いです。
アップスケール Hires.fix について
画像を出力する時にHires.fixにチェックを入れていると解像度を大きくできます。
普通は1.5~2.0倍くらいにします。
大きすぎると出力に失敗しますが、どの程度まで出力できるかはグラボの性能によります。
Hires steps は Sampling steps の半分くらいで大丈夫です。
0の場合は Sampling steps と同じ値になります。
Steps数が多ければ良いというわけではなくて、一定以上はほとんど効果が無いです。
Denoising strength は0.5~0.6の間くらいで設定します。
0.6まで行くと手の位置が変わるなど変化が大きくなります。
0.55くらいまで下げるとおよそアップスケール前の構図のままになるはずです。
VAE設定などを簡単にする Quicksettings list
WebUIの上部にモデル選択をする場所がありますが、そこに項目を追加します。
VAEやClip stopを選択できるようにしておくと便利です。
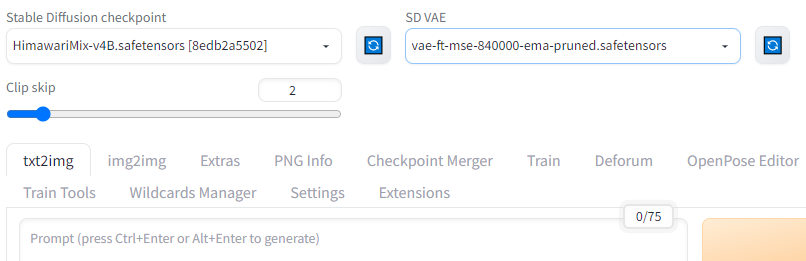
SettingsからUser interfaceへ進んでQuicksettings listの項目を書き換えます。
デフォルトではsd_model_checkpointとなっているので、sd_model_checkpoint, sd_vae, CLIP_stop_at_last_layers と追加してあげることで項目が増えます。
ライブプレビューを切って高速化
画像生成中の状態を表示する機能ですが、オフにしておいた方が速いです。
ライブプレビューがあった方が便利なこともありますが、離席中や睡眠中に生成を行う時は意味がないので切っておいた方がいいと思います。
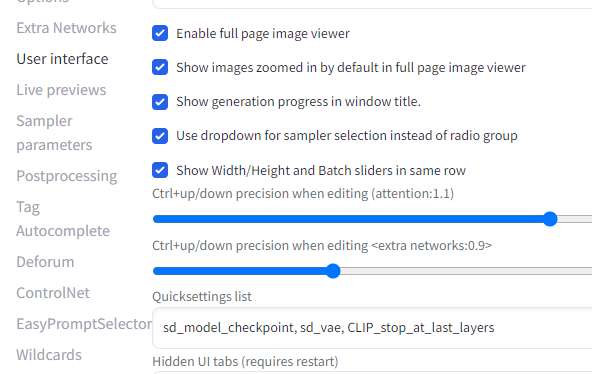
Settings から Live previews を開いて Show live previews of the created image のチェックを外せば完了です。
StableDiffusion起動時の初期値を変更
Stable-diffusion-webui内のui-config.jsonを書き換えると起動時の初期値を変更できます。
中身を見ればだいたいは分かるかと思います。
例えばStepsの数値を弄れば初期のStepsの値が変わります。
ちなみにt2iとi2iで設定が別々になっているので、それぞれ必要に応じて書き換えてください。

メモリリークを解決? sd-webui-memory-release
sd-webui-memory-release
効果があるかは不明。
べつに導入しなくても最悪再起動すれば解決するはず。
生成中にメモリリークっぽい挙動で困ってるなら1回入れてみてもいいかも。
https://github.com/Haoming02/sd-webui-memory-release.git
WebUIの多重起動
ローカルで画像生成する時に多くの場合だとWebUI経由で操作すると思います。
実はこれ多重起動していても全く問題ないです。
もちろん本体自体は並列して動くわけではないので、どちらか一方しか機能しませんが。

基本的に複数タブ開いておく意味は薄いものの、一時的に今の設定を残したまま別の作業をしたい時なんかは便利に使える時があるかもしれないです。
覚えておいて損は無いと思います。
X/Y/Z plot で出力を比較する
WebUIの下の方にScriptという部分があると思います。
そこから X/Y/Z plot を選びます。
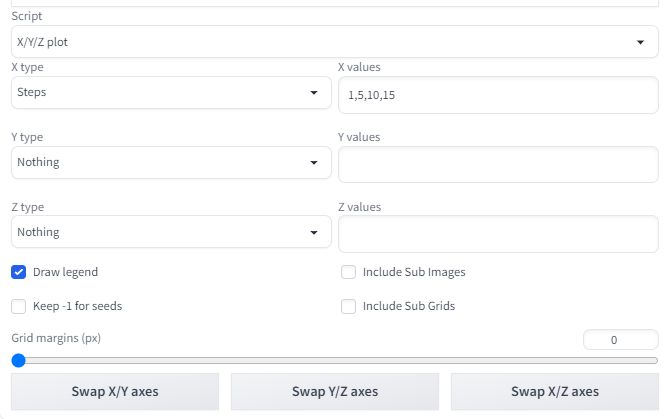
出てきたXYZの欄を必要に応じて選択していきます。
今回は試しに1列だけ生成するのでXだけ選択します。
とりあえずStepsの比較をしようと思います。
右側の欄には比較したいものを入力します。
Stepsなので今回は数字を入れて行きます。
あとは普段通りに生成すれば、各画像とそれを結合した比較画像が生成されます。
