
ControlNetに関連することを色々書いていく記事です。
それっぽい情報は調べていれば結構見かけるんですが、結局よくわからん!みたいなことも多かったので忘備録として残しておきます。
(既出の情報でも参考になる人もいるかもしれないので)
ControlNetを複数使う
MultiCNとか言われても最初はわけわからないと思います。
が、要するにControlNetの機能を複数同時に使って生成しようという話です。
デフォルトだと1つしか利用できないので設定から複数使えるように変更する必要があります。
ControlNetを導入してからSettingsタブを開くと、左側にControlNetの項目が追加されているはずです。
その中からMulti ControlNet: Max models amount (requires restart)の値を増やしてあげます。
デフォルトが1なので1つしか使えませんでしたが、ここの数値を増やせばそれだけ同時に使用できる数が増えます。
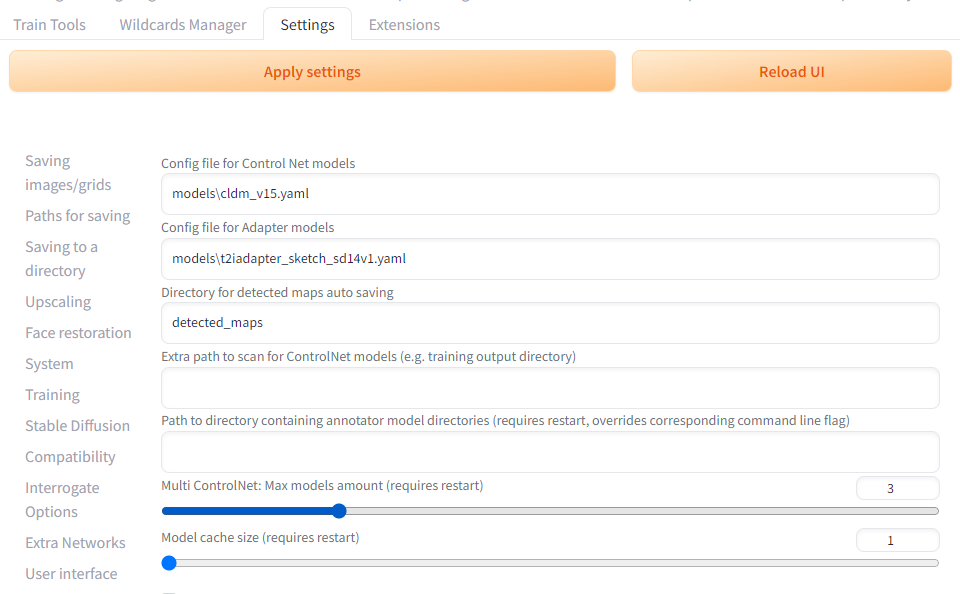
数値をいじったらApply settingsをクリックしてUIをリロードすればモデルが複数利用できるはずです。
ControlNetの中にタブが追加されて増えているのを確認しましょう。
Reference-onlyで似た雰囲気の画像を生成
Reference-onlyとは
各所で話題になったやべぇやつ。
1枚の画像を基に追加学習せずに似た雰囲気の画像を出力できる。
使い方によっては結構危険かもしれないので、その辺りは注意しつつ使ってください。
ちなみに普通に出力するより時間がかかります。
Preprocessorにreference-onlyを設定することでモデルは無しで使用できます。
reference-onlyが表示されない場合はバージョンアップが必要なので、ControlNetをアップデートしてください。
使い方は簡単でControlNetに参考にしたい画像をロードします。
Preprocessorにreference-onlyを設定すると自動でモデル部分はなくなります。
プロンプトは元画像のものを基準として、必要に応じて書き換えを行ってください。
あとはEnableにチェックを入れて生成するだけです。
reference-onlyにはadainとadain+attnというバリエーションがあります。
adain+attnが一番元のスタイルを維持できるようですが、強すぎて扱いにくいためreference-onlyを使うことが推奨されているようです。
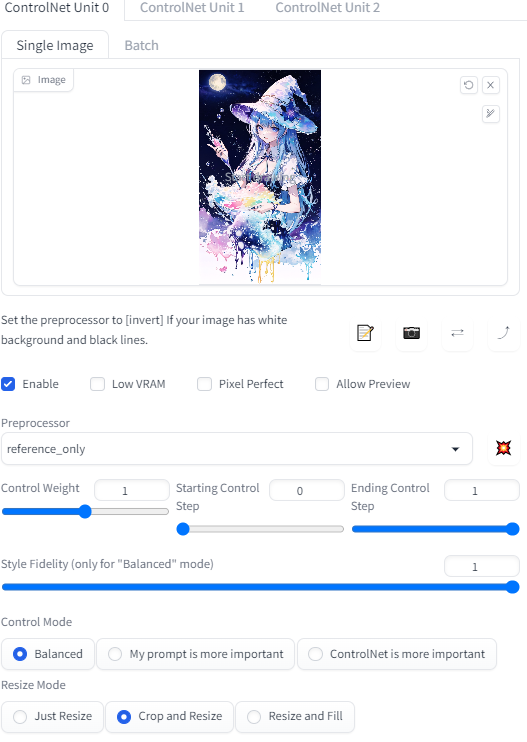
Control Weight の数値を大きくすると元画像にかなり近いものが出力できます。
Style Fidelity の値を変えることでもどの程度元画像を参考にするかを設定できます。
こちらも数値が大きいほど元画像の要素を引き継ぎます。
また、元の画像を出力したモデルと同じモデルを使った方が再現率が高まります。
同系統のマージモデルとかでもかなり近いものが出力できるんじゃないでしょうか。
実際にReference-onlyを使ってみる
今回使っている画像はLoRAも使用したものなので、同一モデルでも同じ出力はちょっと難しいのですが、かなり雰囲気は寄せられていると思います。
ぱっと見ではいい感じだけど右手が変なところに生成されている画像です。
これをベースとして Control Weight 1.7 Style Fidelity 1 に設定して出力しました。
使用モデルは同一です。

best quality, blue dream, watercolor, colorful, 1girl, solo, witch, pastel colors, <lora:makina69_bluedream_v1.0:0.8>
ネガティブ
EasyNegative, (worst quality:1.4), (low quality:1.4), (monochrome:0.6), lowres, bad hand, badhandv4,

best quality, masterpiece,
ネガティブ
EasyNegative, (worst quality:1.4), (low quality:1.4), (monochrome:0.6), lowres, bad hand, badhandv4,
超シンプルなプロンプトですが、かなり近い雰囲気で生成できていると思います。
服装を変えてみる
同様の設定でプロンプトに school uniform を追加しました。
元画像の要素を残しながら服を変えることができました。

best quality, masterpiece, school uniform,
ネガティブ
EasyNegative, (worst quality:1.4), (low quality:1.4), (monochrome:0.6), lowres, bad hand, badhandv4,
ちなみに Multi ControlNet を活用すれば複数枚の画像を参考にして生成することも可能らしいです。
もちろん複数枚使うと生成時間は伸びますが、同一キャラクターを出力したい場合などは有効かもしれません。
Openposeと併用する
別途解説するOpenposeとの併用も可能です。
同じ画像をベースにして、Openposeの項目で使用しているポーズも反映させてみました。
Control Weight 1.5 Style Fidelity 1 プロンプトには school uniform を入れています。
今回は2枚の画像を使うため、ControlNetのUnit0とUnit1を使います。
どちらのUnitもEnableにチェックを入れることで生成画像に反映されます。

best quality, masterpiece, school uniform,
ネガティブ
EasyNegative, (worst quality:1.4), (low quality:1.4), (monochrome:0.6), lowres, bad hand, badhandv4,
手は破綻しているので修正が必要そうですが、画像全体の雰囲気はしっかり引き継がれていますし、ポーズもおおむね指定通りになりました。
後々追記すると思いますが、i2iで使用したり他のCN機能と併用などもできます。
Openposeで姿勢制御をする
プロンプトだけではポーズを指定するのは難しいので、この機能を使って指定してやります。
圧倒的に考えているポーズや構図を出しやすくなります。
とりあえず出力してみる
ControlNetのImageにOpenpose用の画像を読み込みます。
画像は自分で用意してもいいし配布されているものをダウンロードしてきても構わないです。
ポーズはCivitaiでも配布されてますし、別途拡張機能や外部サービスでも生成できます。
順番は前後しますが既存の画像からポーズを出力する方法も解説します。
画像生成時にEnableにチェックを入れることで機能を実行できます。
ポーズ画像を使う場合、PreprocessorはnoneのままでModelにcontrol_sd15_openposeを設定します。
まだダウンロードしていない場合はControlNet-v1-1_fp16_safetensorsから用意します。
stable-diffusion-webui/extensions/sd-webui-controlnet/modelsに配置します。
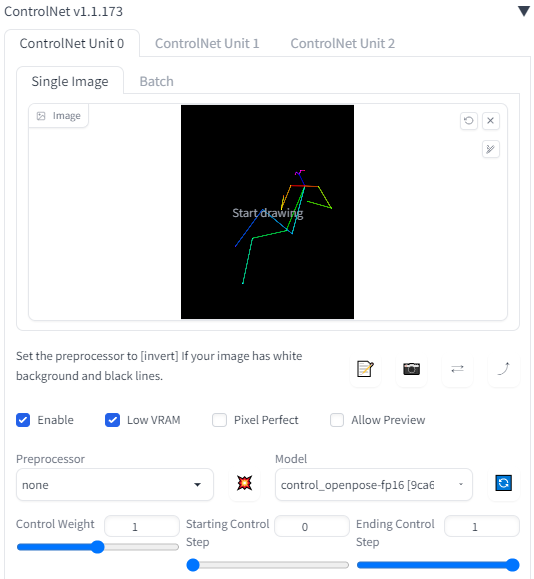
結果はこんなかんじ。

best quality, masterpiece, 1girl, solo,
ネガティブ
EasyNegative, (worst quality:1.4), (low quality:1.4), (monochrome:0.6), lowres, bad hand, badhandv4,
元画像からポーズを引き継ぐ
参考となる画像からポーズを抽出して出力画像に反映させます。
ある程度シンプルな画像でないとうまくいかない事も多いです。
フリーで利用できるシンプルな画像を用意したり、シンプルな3Dモデルでポーズを取らせることができるWEBサービスやアプリは複数あります。
今回はPOSEMANIACSさんから画像を借りてくることにします。
POSEMANIACSさんはTwitterにてAIに利用することを認めています。(フェイク系やポルノ系は禁止とのこと)
とりあえずそれっぽいポーズを使わせてもらいます。
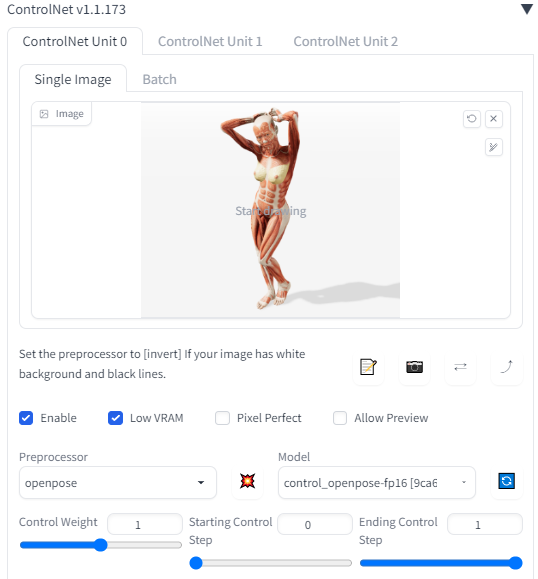
これをControlNetに読み込ませて、preprocessorをopenposeに設定してModelにはcontrol_openpose-fp16を選びます。
Enableにチェックを入れるのも忘れずに。
今回はとりあえず機能さえ使えれば良いのでプロンプトはシンプルにしています。
準備ができたらGenerateで画像を出力します。
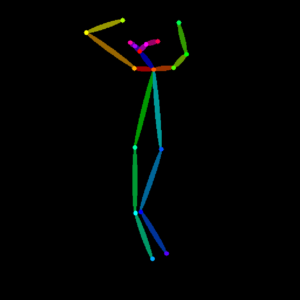
で、出力されたのが以下の画像です。
服装は指定していないので意味わからないことになっていますが、ポーズはおおむね問題なさそうです。

best quality, masterpiece, 1girl, solo,
ネガティブ
EasyNegative, (worst quality:1.4), (low quality:1.4), (monochrome:0.6), lowres, bad hand, badhandv4,
ちなみに一緒にポーズ自体の画像も出力されるので必要に応じて保存してください。
ポーズを作る拡張機能 Openpose Editor
Openpose Editor
ExtensionsタブからInstall from URLへ https://github.com/fkunn1326/openpose-editor.git と入力してインストールできます。
インストールが完了したらタブに Openpose Editor が追加されます。
サイズは見ての通りスライダーで調整できます。
デフォルトで1体表示されていると思いますが、追加したい場合はAddをクリックします。
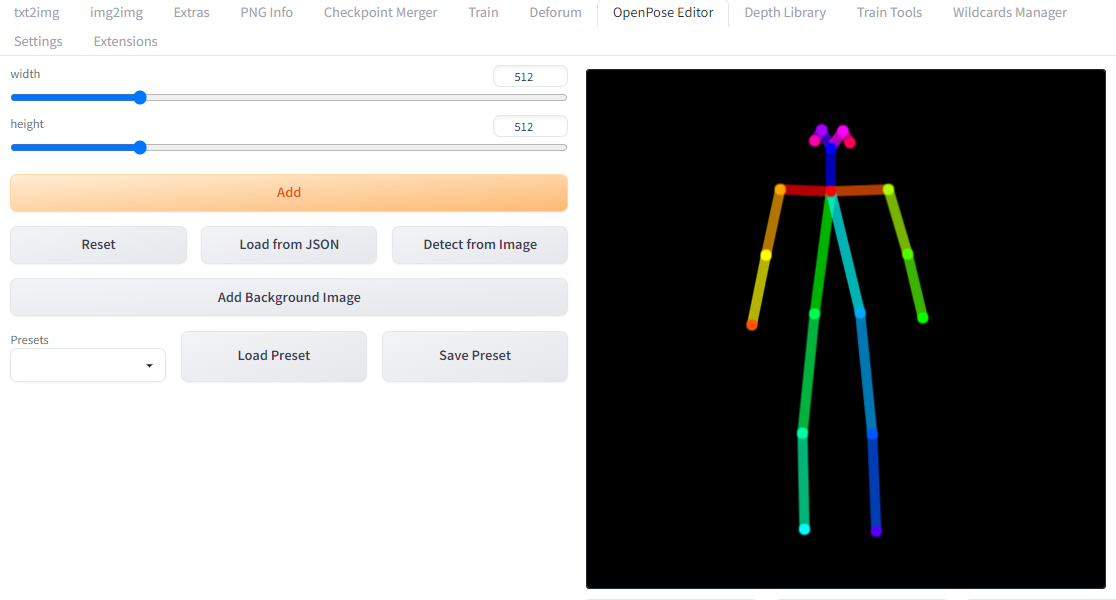
表示されているボーンはドラッグすれば動かせます。
また Detect from Image で画像を読み込むと、その画像からポーズを取り出せます。
ただし複雑すぎだったり一部イラストはうまく抽出できないことが多いみたいです。

画像下のボタンからポーズを管理できます。
Save JSON ではポーズのデータを保存できます。
Save PNG では画像として出力できます。
Send to txt2img ではt2iのControlNetの欄に直接読み込みが行えます。
この拡張機能以外にも3DでいじれるWEBページや対応しているVRMモデルの配布なども存在しているので気になったら調べてみてください。
VRMアバターを使って自分でポーズをとってOpenposeに活用してみた
まずはじめに、様々な機能が登場していますしOpenpose用の素材は簡単に用意できるため、わざわざこの手法を使う必要はほとんどないです。
VRMアバターはVRoidHubなどで公開されています。
もちろん自作しても構いません。
今回はこちらのモデルをお借りしました。
hand付きControl Net用の骨格素材
VRMアバターを動かす方法はいくつもありますが、今回はPC上でポーズを手付けするのではなく、ボディトラッキングをして直感的にポーズを作っていくということをメインにしました。
そのため別件で使用していたVirtual Motion Captureを使いVIVE Trackerでトラッキングを行っています。
指のボーンに関しては手元にNOITOM Hi5 VR GLOVEがあったのでSknuckleを活用させてもらいました。
この辺りはVR機器がないと再現できませんが、WEBカメラでのトラッキングで指まで動かす事も可能だと思うので、その辺りはVRM系の記事を漁ってみることをお勧めします。
で、結果はこんな感じです。
動画キャプチャをした時は背景が水色ですが、ここはVMC側の設定でも簡単に変えられるのでスクショで十分に素材として使えました。
当然と言えば当然ですが、複雑な指はどうしてもうまく出力するのは難しかったです。
機材を用意するのは大変なので日常的にAIイラストに使うのはしんどいとは思いますが、1回準備して様々なポーズを撮影して持っておくのはアリかもしれないです。
Inpaintで画像の一部分だけを書き換える
ちまたで良く見かけるのは手の形が崩れている生成画像の手だけを修正するといった使い方でしょうか。
今回はとりあえず比較的簡単にできそうな顔(表情)の書き換えだけやる流れを書こうと思います。
普段通り画像を生成する
とりあえずt2iで出力してみます。
別に既存の画像でもいいみたいなんですが、t2iで出力した画像が一番楽だと思います。
とりあえず機能を試してみたいだけならプロンプトは簡素な感じでいいんじゃないでしょうか。
画像を出力した後 Send to i2i をクリックすれば、出力した画像が勝手にi2iのタブに読み込まれると思います。
もし勝手に移動しなかったら手動で移動してプロンプトとかもコピペしましょう。
過去に出力した画像を使う場合は手動で読み込むことになると思います。
プロンプトとネガティブプロンプトも欲しいので PNG info に読み込んで情報を取り出してください。
変更箇所を指定するためのマスク作成
画像の編集なんかをやったことならマスクの概念は分かると思います。
それ以外でもマスキングテープとか聞いたことあるんじゃないでしょうか。
簡単に言うと画像の任意の部分を塗りつぶして、塗りつぶした部分を保護するといったイメージです。
デジタル上のことなので塗りつぶした部分を保護するか、逆に塗りつぶした部分だけを変更するか簡単に切り替えできます。
基本的には一部分だけを変化させたい事が多いと思うので、実際には塗った部分を変更する方を頻繁に使うと思います。
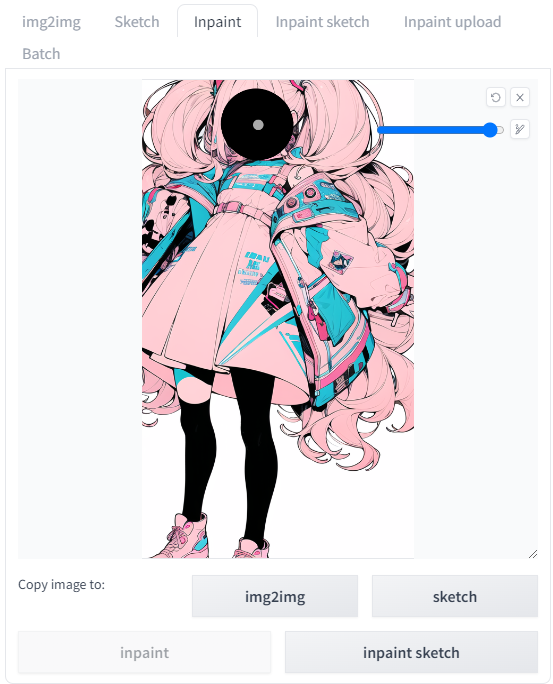
今回はとりあえず変更を行いたい部分だけ塗りつぶすことにします。
Inpaintを選択して顔をてきとーに塗ります。
本当はもっと細かくした方が仕上がりはいいと思います。
ただ今回みたいにとりあえず機能を体験するだけなら大雑把で構わないです。
ぶっちゃけマスクの塗りつぶし作業はWebUI上だと操作しにくいです。
必要最低限の操作はできるので問題はありませんが、外部で処理したい場合もあると思います。
そういう時はInpaint uploadから処理済みの画像を読み込ませてください。
プロンプトや出力の設定
まずはどのように変更したいかをプロンプトで指定します。
元のプロンプトのコピペから一部書き換える感じでいいと思います。
出力画像によっては元のプロンプトを入れなくてもそれっぽい感じになるかもしれませんが、基本的には元のプロンプトの一部を改変するような手法がいいと思います。
今回はとりあえず笑顔で赤目にします。
smile, red eyes とプロンプトに追加しました。
プロンプト入力が終わったら出力の設定です。
とりあえず今回の設定をキャプチャしたものを載せます。
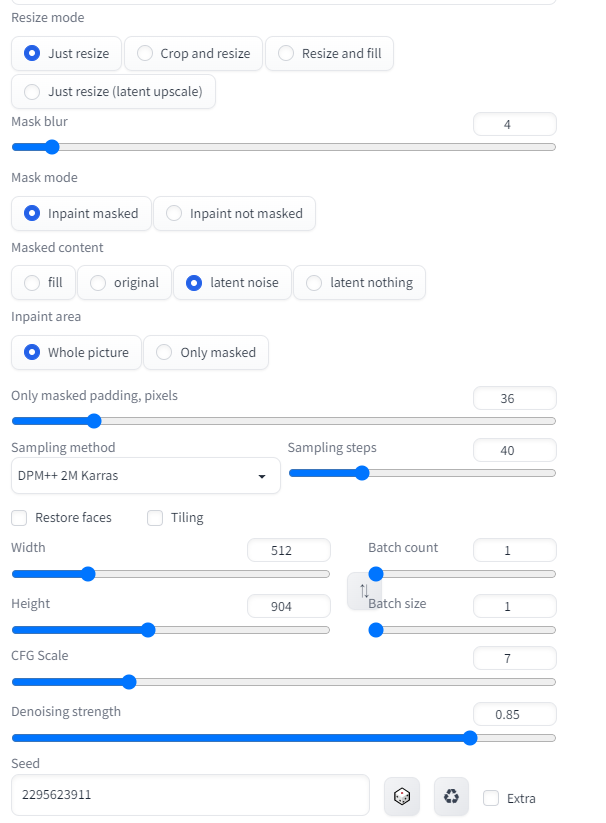
Resize mode
リサイズに関する設定です。詳しくは4種とも実際に試すのがいいと思います。
今回は元画像と同じアスペクト比で出力するのでJust resizeのまま進めます。
Just resize
この先で指定する解像度に出力結果を合わせてくれますが、元画像のアスペクト比と出力したい画像のアスペクト比が異なる場合、元画像の比率を無視して引き延ばしされます。
アス比が同じなら何ら問題ないはず。
Crop and resize
縦横比をそのままに出力したい解像度まで引き延ばして、その後にはみ出した部分をトリミングします。
勝手にはみ出した部分がトリミングされるのでめっちゃ使いにくいです。
Resize and fill
アスペクト比を守ったままサイズを調整して、足りない部分を追加で書き足してくれるモードです。
迷ったらとりあえず選んでおいて、追加された部分が不要なら後でトリミングすれば良さそう。
Just resize
ほぼ Just resize と同じようなことをしているみたいです。
アップスケールの中身が違うだけっぽい?
Mask blur
マスク部分を再生成する際にどれくらい回りと馴染ませるかみたいな値だと思う。
要するにマスク範囲とそれ以外の範囲の境界をどれくらいぼかすかという感じ。
とりあえず初期値のままで1回生成してみて、不自然な感じだったり思ったより変化しちゃった場合は弄って見ると良い。
数値を下げれば再生成の影響が小さくなる。
Mask mode
塗った部分を再生成するか、塗った部分を保護してそれ以外の部分を再生成するかの選択。
今回は Inpaint masked を使うけど用途によって楽な方で。
Masked content
再生成する部分をどのように生成するのかを決定する項目です。
fill
周囲の色を使ってマスクした範囲を塗りつぶしてくれます。
基本的に再出力された範囲に元々あったものは消えます。
original
元画像の感じをベースに生成します。
微調整したい時なんかは良い感じだと思います。
latent noise
マスクした範囲を一度ノイズ画像にして再生成します。
要するに元画像の事なんか知らねー!この部分だけ勝手に生成するぜ!って感じです。
元画像の影響を受けずに好きなように生成することができますが、周りと馴染まないものが生成されることも多いです。
latent nothing
マスク範囲内の色を使ってマスク範囲を塗りつぶしします。
個人的には使い道少ないように感じますが、どこかで使う事あるのかもしれないので覚えておいて損は無さそう。
Inpaint area
Whole pictuer は画像全体をサイズそのままにして再生成を行います。
Only masked はマスク範囲だけを一旦切り出して、指定している解像度に引き延ばしてから再生成を行い、その後に縮小して元の位置にはめ込むような挙動になります。
低解像度の場合は Whole pictuer で特に違和感はないと思います。
解像度の高い画像の一部の描き込みを増やしたい場合などは Only masked の方が良さそうです。
Only masked padding, pixels
Only masked を選んだ時に何ピクセル余白を設けるかという設定らしい。知らんけど。
とりあえず初期値で使ってて特に問題なかったので極端な数値にしなければ大丈夫そう?
体感だと細かく弄る必要性はあまり感じないです。
Whole picture は画像全体はそのままでマスク部分だけ修正していますが、一方で Only masked はマスク範囲だけを切り取って拡大して再生成後に元の位置にはめ込む感じの挙動をします。
この切り取る時にここで設定したピクセル数だけ範囲を広げてくれるということみたいです。
その他の設定
sampling method はとりあえず元画像と同じのを選択するのが無難。
steps や CGF Scale についても元画像を基準にして、必要に応じて調整するといいと思います。
Denoising strength の値は0に近づくと変化が減り、1に近づくとほぼ出力しなおしみたいな感じのイメージです。
基本的に小さすぎると変化がないのである程度の数値にする必要はあります。
画像によって最適な数値は全く異なると思うので、0.3くらいで良いケースもあれば0.7以上欲しいこともあります。
Seed値も元画像から流用すると安定するので、直前に生成したものならリサイクルマークみたいなやつで呼び出して使いましょう。
ただ別のSeed値でも普通に生成できるので、その辺りは出力結果との兼ね合いで色々試してみるといいと思います。
直前の画像でない場合は PNG info からSeed値を取り出すかファイル名からコピペで後からでも確認できます。
(出力ファイル名は設定でどの情報を表示するか変わるので、設定次第では見れないかもしれないです。)
出力結果
左が元画像で右が変更後です。
結構良い感じに変わったんじゃないかと思います。
今回は範囲が適当だったのと再生成方法の関係で髪の毛の流れる方向まで変わってしまいましたが。


単体のイラストとしては手の修正や細かい部分の修正需要が高そうです。
今回みたいに表情を変更する方法もゲームキャラクターの表情差分なんかには使えるんじゃないでしょうか。
Only masked でも出力してみる
おまけで Only masked で顔を修正するパターンも載せておきます。
とりあえず細部はおいといて適当に出力した画像の顔を高解像度化してみます。

とりあえずi2iの画面でマスク塗るところまでやります。
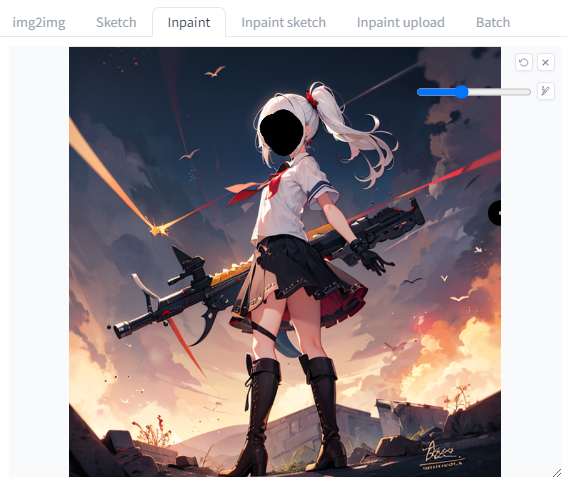
Only masked で顔部分だけめっちゃ引き延ばして描き込む感じの設定をしました。
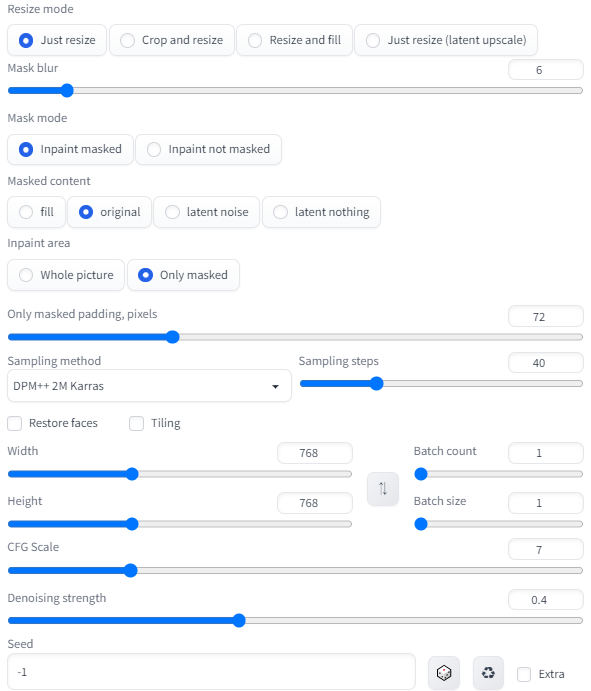
その結果がこんな感じです。
だいぶ顔の描き込みが改善したように思います。
